
티스토리 뷰
728x90
https://school.programmers.co.kr/learn/courses/30/lessons/17684
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr

1. 접근 방식
- key가 알파벳이고 value가 색인 번호인 기본 사전을 생성하자.
- msg의 글자를 순회할 때 for문이 아닌 while문을 사용하자.
예를 들어 msg가 "...TOBEOR..."이고 현재 입력 w가 TOB일 때, 다음에 접근해야 할 문자는 T 다음 문자인 O가 아니라, TOB 덩어리 다음인 E이다. 즉, msg 내 문자를 하나씩 순회하지 않기 때문에 TOB의 T 인덱스가 i일 때 다음에 i + len('TOB')에 접근할 수 있도록 while문을 사용한다.
- 사전에 존재하는 단어를 뽑아내기 위해서는 가장 긴 문자부터 고려하자.
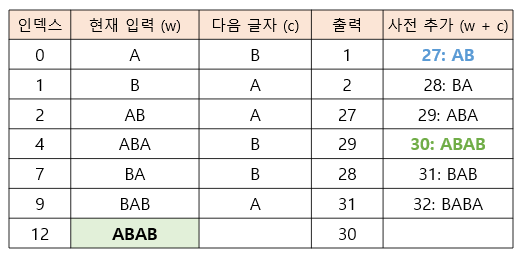
예를 들어 ABABABABABABABAB의 마지막 ABAB에서 처음 시작하는 문자 A의 인덱스는 12이다. 만약 인덱스 12에서 하나씩 늘려가면서 A, AB, ABA, ABAB 순서로 사전에 문자가 존재하는지 찾는다면 ABAB가 사전에 존재하여도 더 짧은 A를 계속 반환해버릴 것이다. 이는 비단 ABAB만의 문제가 아니라, 당장 3번째 AB부터 발생하는 문제이다.
따라서 현재 인덱스가 i = 9라면 BABABAB, BABABA, BABAB, BABA, BAB...처럼 j = len(msg)로 두고, mgs[i:j]가 사전에 없다면 j를 계속 -1하면서 msg[i:j]가 사전에 존재할 때까지 반복하는 방식을 생각했다.
2. 정답 코드
def make_basicDictionary():
from string import ascii_uppercase
return {c: i for i, c in enumerate(ascii_uppercase, 1)}
def solution(msg):
d = make_basicDictionary()
i, added_index = 0, 27
count = len(msg)
answer = []
while i < count:
j = count
while msg[i:j] not in d:
j -= 1
answer.append(d[msg[i:j]])
d[msg[i:j+1]] = added_index
added_index += 1
i += len(msg[i:j])
return answer
728x90
'코딩 테스트 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] 입국심사 파이썬 풀 (0) | 2024.02.05 |
|---|---|
| [프로그래머스] H-index 파이썬 풀이 (0) | 2024.02.03 |
| [프로그래머스] 베스트앨범 파이썬 풀이 (0) | 2023.06.25 |
| [프로그래머스] [1차] 셔틀버스 파이썬 정답 코드 (0) | 2023.06.23 |
| [프로그래머스] k진수에서 소수 개수 구하기 파이썬 정답 코드 (0) | 2023.06.20 |